kubenetes 核心概念之 Pod

kubenetes 核心概念之 Pod
双木老林概述
- k8s 中创建和管理的最小单元。
- 包含一个或多个 container 容器
- 一个 Pod 中的容器共享网络命名空间
- Pod 是短暂的
实现机制
共享网络机制
docker container 之间是相互隔离的,要实现共享网络,需要实现容器在同一个 namespace 之下。
Pod 实现共享网络机制的过程:
- 创建 Pause 容器(根容器、info 容器)
- 创建业务容器
- 将创建的业务容器加入到根容器中
- 循环 2-3
共享存储机制
通过 Volumn 数据卷实现(持久化存储)
镜像拉取策略
- IfNotPresent: 默认值,不存在才拉取
- Always: 每次都重新拉取
- Never: 从不拉取
Pod 资源限制
根据配置的资源限制,完成适合的调度。
- Request: 容器使用的最小资源需求,作为容器调度时资源分配的判断依赖。只有当节点上可分配资源量 >= 容器资源请求数时才允许将容器调度到该节点。但 Request 参数不限制容器的最大可使用资源。
- Limit: 容器能使用资源的资源的最大值,设置为 0 表示使用资源无上限。
1 | spec: |
Pod 重启策略
- Always: 默认值,当容器终止退出后,总是重启容器
- OnFailure: 当容器异常退出(退出状态码 != 0)时才重启容器
- Never: 从不重启
1 | spec: |
Pod 健康检查
Docker-container 时,判断状态是否正常是通过判断容器状态,但是一些异常并未能导致容器宕掉,例如 Java堆内存溢出,此时要判断是否正常则需要进入应用层进行判断,k8s 提供了俩种检查机制
livenessProbe(存活检查)
如果检查失败,将杀死容器,根据 Pod 的 restartPolicy 来操作
readinessProbe(就绪检查)
如果检查失败,k8s 会把 Pod 从 service endpoints 中剔除
Probe 支持以下三种检查方法:
httpGet
发起 HTTP 请求,返回 200-204 范围状态码为成功
exec
执行 shell 命令,返回状态码是 0 则成功
tcpSocket
发起 TCP Socket 建立成功则成功
调度策略
创建一个 Pod 的过程
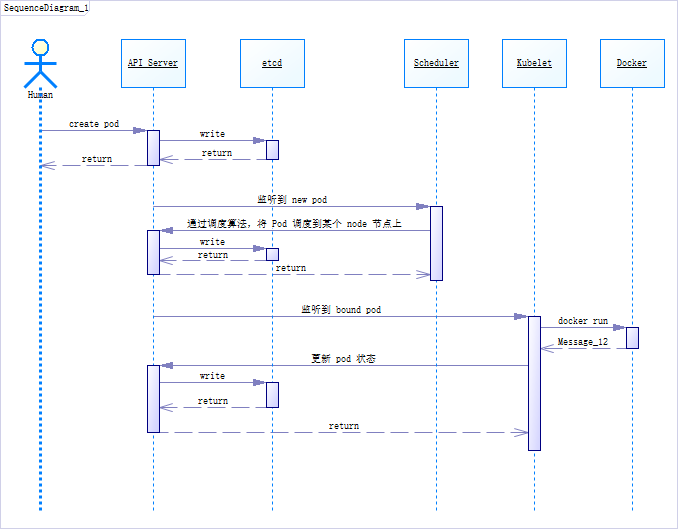
master 节点干的事:
- 在 API Server 中创建好 Pod,然后将信息写到 etcd 中
- Scheduler 实时通过 Api Server 监听到有新的 Pod 创建,通过调度算法,把 Pod 调度到某个 node 节点上,后通过 API Server 写到 etcd 中
node 节点干的事:
- kubelet 到 API Server 查看,读取 etcd 拿到分配给当前节点的 Pod 信息,通过 docker 创建对应的容器,完事后通过 API Server 写到 etcd 中
影响 Pod 调度的属性
Pod 资源限制
1 | spec: |
节点选择器标签
1 | spec: |
- 对 node 节点创建标签
1 | kubectl label node node1 env_role=dev |
节点亲和性
节点亲和性 nodeAffinity 和 节点选择器 nodeSelector 基本一样,都是根据节点上标签约束来决定 Pod 调度到哪些节点上
1 | spec: |
强亲和性
约束条件必须满足,如果没有满足的 node,则会一直等待
软亲和性
尝试满足约束条件,但是不保证满足条件(例如资源不足),将部署到集群中的其他节点
支持的常用操作符
也就是上面的 yaml 中的 operator 取值
- In
- NotIn
- Exists
- Gt
- Lt
- DoseNotExists
污点和污点容忍
nodeSelector 和 nodeAffinity: 作用是将 Pod 根据配置调度到某些节点上,这俩属于 Pod 的属性,在调度的时候实现。
Taint 污点: 节点不做普通分配调度,Taint 是节点的属性
取值如下:
- NoSchedule: 一定不被调度
- PreferNoScheduler: 尽量不被调度
- NoExecute: 不会被调度,并且会驱逐当前 node 已有的 Pod
使用:
1 |
|
使用场景
- 专用节点
- 配置特点硬件节点
- 基于 Taint 驱逐
污点容忍
1 | spec: |
当增加了污点容忍的节点,即使本身拥有着污点,也可能会被调度到,当然也可能不被调度。















